


How do you use AI to summarize text?
With the explosion of natural language tools like ChatGPT - let's look at how text summarization can help organizations


Have you ever read an interesting book that sometimes gets too long - and you just want a summary of? Sure there are websites like blinkist that use human readers to summarize books to which you can subscribe, but that is not always convenient to access. Also, organizations can have internal documents containing sensitive customer information that they want to summarize and would prefer to use automated methods.
Just the other day, someone on LinkedIn wanted my feedback on extracting values from contractual documents such as customer name, contract duration, invoice details, etc. Summarization could potentially be very useful. And current developments in AI could make summarization of long complex documents in a short time - a reality.
So let’s dig into how to create summaries using state of the art natural language processing.
How do Machine Learning models generate summaries?
There are 2 types of summarization - abstractive and extractive summarization. Abstractive summarization paraphrases the original document into a shorter version, but generates new summaries. Whereas extractive summarization chooses certain key phrases from the original article.
Which model you choose depends on your needs. Abstractive summarization is good if you want something independent of original text, but containing the main points. Think of an app that summarizes key research findings over the week in a certain field. The abstractive summary can be 3 sentences from the original papers.
Whereas extractive summarization could be useful in information extraction tasks. Say you wanted to extract quotes or customer specific information from contracts and you want the model to output the sentences containing the relevant information, and you don’t care so much if the summary appears more choppy.
Under the hood, modern summarization models rely on transformers, a type of ML model that has taken the Natural Language Processing (NLP) world by storm since 2017.
BERT is a transformer based model that was trained in an unsupervised fashion - to predict masked words in word documents. This is a test commonly administered test mastery of a language. Thus by training BERT in this manner, it became a general expert at the English language.

BERT models can be trained downstream on a variety of extraction tasks including question answering, named entity recognition, and extractive summarization as shown below.
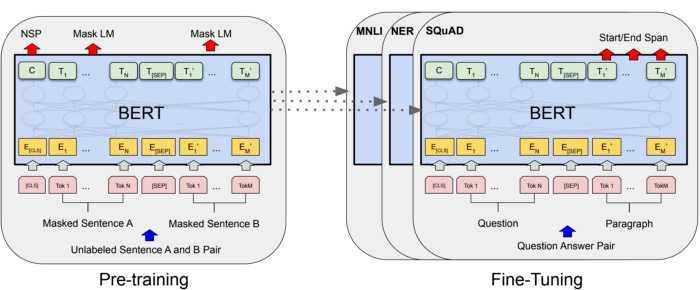
Abstractive summarization on the other hand can be performed by text to text models like T5 and BART. Basically, you can think of summarization as similar to translation; except - instead of converting to another language, you are converting to a smaller version that is not a subset of the original text.
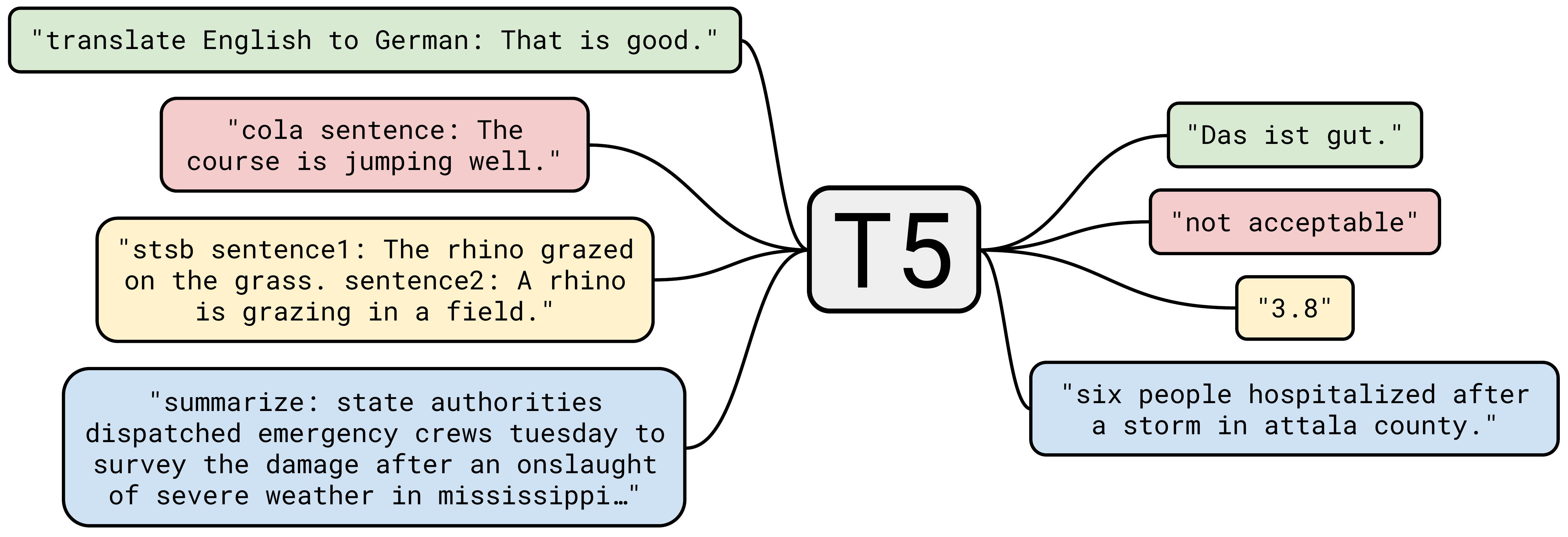
How to label, train and evaluate summarization models
Labeling data for summarization models is easy in principal. All you need is to generate summaries of articles and train your ML model on these summaries. However, generating these summaries is not easy. Unlike classification tasks such as positive or negative sentiment - generating summaries requires human expertise and maybe even subject matter experts in some cases.
There are many open access data sources like the CNN-DailyMail and XSum datasets that used clever methods to generate hundreds of thousands of summaries. As a starting point - these are good resources for obtaining general summaries of articles, though they might not be suitable for specific tasks for example extracting only medical related contents from articles.
Finally, evaluation - how do you know one summarization model does better than another? You would basically need someway of comparing model generated summaries with human “golden summaries.” This can be done by simply finding the overlap in words between model summaries or golden summaries. Another type of metric known as the ROUGE-N metric measures the 1 word (unigram), two-word (bigram), three-word (trigram) or in general the N gram overlap between model and golden summaries. The ROUGE-L metric looks at the longest matching sequence of words between model and golden summaries.
Summarization models on HuggingFace
Hugging Face is a company that aims to advance AI through open source. Hugging Face hosts a number of language models and it is quite intuitive to use their APIs. Here is the code snippet to load 2 different summarization models - both of which are from the same original distilBART model, but fine-tuned on different data sets (CNN vs XSUM).
As you can see, the first model (finetuned on the CNN-DailyMail dataset) does reasonably well but maybe a little long. The 2nd model (finetuned on the XSUM dataset) gives a shorter summary. But note that the summary does not capture the jist of the article about the structure and history of Eiffel Tower - and instead reads as a news article; as if the Eiffel Tower has recently opened it’s doors to the public(which might be misleading).
The thing to keep in mind is that while shorter summaries are preferrable - they can often lose the important information, like “throwing the baby out with the bath water.”

Future Outlook
Hopefully this article has shown you just how easy it is to get a summarization from a state of the art AI model and your head is spinning with the endless possibilities of article summarization for your needs!
You might also be thinking that there is still so much to be done in summarization and this niche field is still in it’s infancy. While we have not yet seen tools that summarize entire books into neat bullet points as well as a reader might - this is coming soon. Though I didn’t go into detail - with the right data and architectures, it is possible to do summarization in niche fields by fine-tuning transformer models on custom labeled data.
I’m in the process of building an AI based summarization tool which will be a website app - and I plan to give API access to those that would like to use this tool. If you want to collaborate on this or discuss - feel free to reach out as a comment or just by replying to this email if you are a subscriber!
The code for generating summaries based on Hugging Face models in Google Colab is here!
If you enjoyed this post, please share on social media or even just one person you think might enjoy holistic perspectives on the interconnections between technology and modern societies. Feel free to also post any comments in the post discussions on the cyber-physical substack page. This is a small, but growing effort and I hope that I can share in my journey in understanding and building resilient societies.