


LLM Economics: ChatGPT vs Open-Source
How much does it cost to deploy LLMs like ChatGPT? Are open-source LLMs cheaper to deploy? What are the tradeoffs?

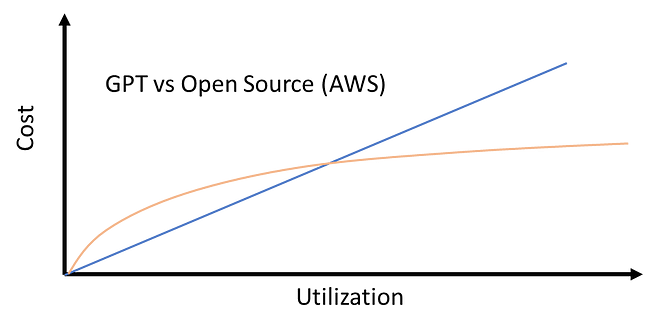
TLDR: For lower usage in the 1000’s of requests per day range ChatGPT works out cheaper than using open-sourced LLMs deployed to AWS. For millions of requests per day, open-sourced models deployed in AWS work out cheaper. (As of writing this article on April 24th, 2023.)
Large Language Models are taking the world by storm. Transformers were introduced in 2017, followed by breakthrough models like BERT, GPT, and BART — 100’s of millions of parameters; and capable to performing multiple Language tasks like sentiment analysis, Q&A, classification, etc.
A couple of years ago — researchers from OpenAI and Google documented multiple papers showing that large language models with more than 10’s of Billions of parameters started showing emergent capabilities where they seemingly understand complex aspects of language and are almost human-like in their responses.
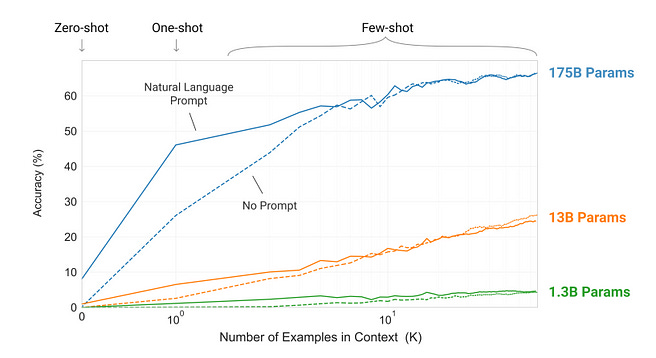
The GPT-3 paper showed that models > 10-100 Billion parameters show impressive learning capabilities with just a few tens of prompts.
However, these LLMs are so resource intensive that they were economically challenging to deploy at scale. That is, until the recent arrival of ChatGPT. Soon after the ChatGPT interface was released, OpenAI made the ChatGPT API accessible, so developers could use ChatGPT in their applications. Let’s see how much these cost at scale and the economic viability.
ChatGPT API costs
The ChatGPT API is priced by usage. It costs $0.002/1K tokens. Each token is 3/4th a word roughly — and the number of tokens in a single request is the sum of prompt + generated output tokens. Let’s say you process 1000 small chunks of text per day, each chunk being a page of text — so 500 words or 667 tokens. This comes to $0.002/1000x667*1000= ~$1.3 a day. Not too bad!
But what happens if you are processing a million such documents a day? Then it is $1,300 per day or ~0.5 Million$ per year! ChatGPT goes from being a cool toy to being a major expense (and consequently one hopes — a major source of revenue) in a multi-million dollar business!
Opensource Generative Models
After ChatGPT came out, there were a bunch of open source initiatives. Meta came out with LLaMA — a 10’s of billions of parameters LLM model that outperforms GPT-3. Stanford then fine-tuned the 7B version of LLaMA on 52K instruction-following demos and found that their Alpaca model outperformed GPT-3.
A team of researchers also recently showed a 13B parameter fine-tuned LLaMA model called Vicuna acheived >90% of ChatGPT quality. There are multiple reasons why companies might choose to use opensource generative models instead of the GPT family of models from OpenAI. These include less susceptibility to OpenAI outages, easier to customize, and possibly cheaper.
While open source models are free to use, the infrastructure to host and deploy them is not. And while earlier transformer models like BERT could easily be run and fine-tuned on personal computers with a good CPU and basic GPUs, LLMs are more resource intensive. A common solution is to use cloud providers like AWS to host and deploy such models.
Let’s dive into AWS costs for hosting open source models.
AWS costs
First, let’s discuss the standard architecture for deploying models in AWS and serving them as APIs. Usually there are three steps:
Deploying the model as an endpoint usingAWS Sagemaker.
Connecting the Sagemaker endpoint to AWS Lambda.
Serving the Lambda function as an API through API Gateway

When the client makes an API call to the API Gateway, it triggers the lambda function, that parses the function and sends it to the Sagemaker endpoint. The model endpoint then does the prediction, and sends the information to Lambda. Lambda parses this and sends it to the API, and eventually back to the client.
The Sagemaker costs are sensitive to the type of computing instance for hosting the model. LLMs use rather large computing instance.
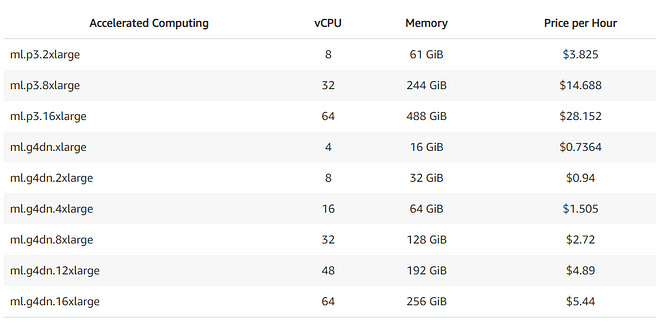
For example, this article written by someone from AWS details how to deploy Flan UL2 — a 20 Billion parameter model, on AWS
The article used the ml.g5.4xlarge instance. While the Sagemaker pricing above didn’t list the cost for this specific instance price, it seems like it would be in the ballpark of ~5$ per hour. Which comes to 150$ per day! And this is just for instance hosting, we haven’t yet come to the Lambda and API Gateway costs.
Below details the AWS lambda pricing — which is a function of memory usage and frequency of requests.

Let’s say it takes 5s for obtaining a response. 128 MB is plenty given we are routing the data to the AWS Sagemaker endpoint. So this would cost 5*.128*1000*$0.0000166667= 0.01$ for 1000 requests, or 10$ for 1M requests.
And the final cost is for the API gateway:
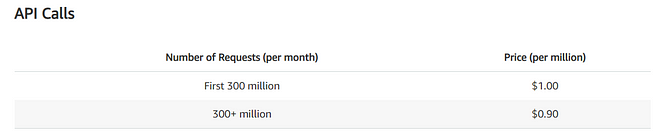
As you can see, the API Gateway is pretty cheap — 1$ per million requests.
So ultimately the cost of hosting an open-source LLM like Flan-UL2 on AWS is 150$ for 1000 requests a day, and 160$ for 1 M requests a day.
But do we always need such costly computing instances? For smaller language models like BERT that are 100’s of millions of parameters — you can get away with using cheaper instances like ml.m5.xlarge that is $0.23/hour and ~5$ a day. These models are also pretty powerful, and are more task and training data specific as compared to LLMs that seem to understand the complex nuances of language.
Closing Thoughts
So which is better? Using paid service LLMs like OpenAI’s GPT series? Or open-access LLMs? It depends on the use case:
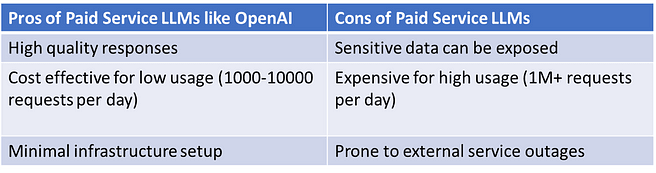
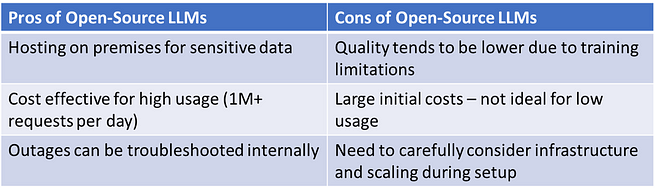
Note: Since this is such a rapidly advancing field, it is quite possible that due to the large-scale demands, in the relatively near future, deployment costs drastically reduce. (Keep in mind that while hosting open-source LLMs is a challenge, smaller language models like BERT that have 100’s of millions of parameters are still a great option for specific tasks. I’ve written articles on how fine-tuning BERT based models on tasks like question answering and spam detection can yield near human performance.)
But which model is better? The responses from ChatGPT and GPT-4 are more relevant than those from open-source LLMs. However, open-source models are catching up quickly. And there might be very good reasons for using open source models rather than closed APIs.
Companies want to fine-tune open source models on their specific data sources. ChatGPT and subsequent OpenAI models might not perform as well as open sourced models fine-tuned on domain specific data; due to the generic nature of such models. Already, we are seeing domain specific models like BloombergGPT making powerful moves in Generative AI.
Oh — and let’s all pray that OpenAI does not hike the price of the ChatGPT API. When the ChatGPT API came out it was pleasantly surprising that the API was priced 10X cheaper than the earlier GPT-3 API.
We live in exciting times!
Note: this article was originally published on Medium, in April of 2023 but is now under a strict paywall - since then, many things have changed, but the basic premise remains relevant :)